
继续Big编码的扩展隐射及解决方法
By:Roy.LiuLast updated:2025-12-03
在昨天利用AI解析编码之后,最后采用了Big5到GB2312的转换,这样的转换能解决绝大多数的问题。但从数据库中获取的记录,还是有部分转换之后会出现"?"字符,说明转换不了。将这些有问题的文本拷贝一个到Idea代码编辑器中,呈现出:笢\uF6EA珛憎 的样子, 如果拷贝到notpad,会出现: 笢?珛憎。说明转换还是有一些问题。
在网上收集了一点,关于香港那边的编码相关的东西。在拷贝出来的文本中出现了 \uF6EA 专业的字符, \uF6EA(U+F6EA)属于 Unicode 的私用区(PUA)。PUA 字符经常是从 Big5 / HKSCS / 厂商扩展表映射过来的,也就是说某次把字节按 Big5/HKSCS 等映射到 Unicode 时,映射表把某个 Big5 扩展码位映射成了 U+F6EA,这说明在导出/复制/粘贴的某个环节使用了带扩展的 Big5 映射(或类似厂商映射),而在你当前查看、希望得到简体字的环境里则应当把原始字节用 GBK/GB18030/CP936 解回去。要准确恢复原始简体字,最可靠的是拿到“原始字节”(即导出的文件的二进制内容)并尝试不同的解码表(Big5、Big5-HKSCS、CP950、GB18030 等),重新生成一段代码解析的工具类:
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class EncodingRecover {
// 常见候选编码(可按需扩展)
private static final String[] CANDIDATES = {
"UTF-8", "UTF-16LE", "UTF-16BE", "UTF-16",
"GB18030", "GBK", "GB2312", "CP936",
"Big5", "Big5-HKSCS", "x-windows-950", "CP950",
"ISO-8859-1", "Windows-1252", "US-ASCII", "Latin1"
};
public static void main(String[] args) {
testString("笢\uF6EA珛憎");
}
public static void main1(String[] args) throws Exception {
if (args.length == 0) {
// 默认测试示例:你给的字符串
testString("笢\uF6EA珛憎");
System.out.println("\nUsage examples:");
System.out.println(" java EncodingRecover <your-string-quoted>");
System.out.println(" java EncodingRecover -file exported.csv # 尝试用多种编码直接解码文件 bytes");
return;
}
if ("-file".equalsIgnoreCase(args[0]) && args.length >= 2) {
Path p = Paths.get(args[1]);
if (!Files.exists(p)) {
System.err.println("File not found: " + args[1]);
return;
}
byte[] raw = Files.readAllBytes(p);
tryDecodingsFromBytes(raw);
return;
}
// join args into one string
StringBuilder sb = new StringBuilder();
for (int i = 0; i < args.length; i++) {
if (i > 0) sb.append(" ");
sb.append(args[i]);
}
testString(sb.toString());
}
private static void testString(String s) {
System.out.println("Input Java String: " + s);
System.out.print("Code points: ");
for (int i = 0; i < s.length(); ) {
int cp = s.codePointAt(i);
System.out.printf("U+%04X ", cp);
i += Character.charCount(cp);
}
System.out.println("\n");
// 显示把该字符串用各种编码 encode 后的 bytes hex
System.out.println("=== encode(displayedString) -> show bytes hex for various encodings ===");
for (String enc : CANDIDATES) {
try {
byte[] b = s.getBytes(Charset.forName(enc));
System.out.printf("%-12s : %s%n", enc, toHex(b));
} catch (Exception e) {
System.out.printf("%-12s : (error: %s)%n", enc, e.getMessage());
}
}
// 穷举 encode(displayed) -> decode(candidate) 的组合(模拟常见修复)
System.out.println("\n=== Try encode(displayed)->decode(candidate) combinations ===");
for (String encFrom : CANDIDATES) {
for (String encTo : CANDIDATES) {
try {
byte[] bytes = s.getBytes(Charset.forName(encFrom));
String cand = new String(bytes, Charset.forName(encTo));
if (looksReasonable(cand)) {
System.out.printf("%-12s -> %-12s : %s%n", encFrom, encTo, cand);
}
} catch (Exception ex) {
// ignore
}
}
}
System.out.println("\nNOTE: Focus on lines where the right-hand side shows readable Simplified Chinese (或你期望的文本).");
}
private static void tryDecodingsFromBytes(byte[] raw) {
System.out.println("Input bytes length: " + raw.length);
System.out.println("=== try decoding raw bytes with candidate encodings ===");
for (String enc : CANDIDATES) {
try {
String dec = new String(raw, Charset.forName(enc));
String snippet = dec.length() > 400 ? dec.substring(0, 400) : dec;
System.out.println("---- decode as " + enc + " ----");
System.out.println(snippet);
} catch (Exception e) {
System.out.println("---- decode as " + enc + " ----");
System.out.println("decode error: " + e.getMessage());
}
System.out.println();
}
System.out.println("If one decode shows correct Simplified Chinese, that is your recovery encoding.");
}
private static boolean looksReasonable(String s) {
if (s == null || s.isEmpty()) return false;
int cjk = 0, ascii = 0;
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
if (ch >= 0x4E00 && ch <= 0x9FFF) cjk++;
if (ch >= 32 && ch <= 126) ascii++;
}
return cjk > 0 || ascii == s.length();
}
private static String toHex(byte[] b) {
StringBuilder sb = new StringBuilder();
for (byte x : b) sb.append(String.format("%02X", x));
return sb.toString();
}
}结果如下:
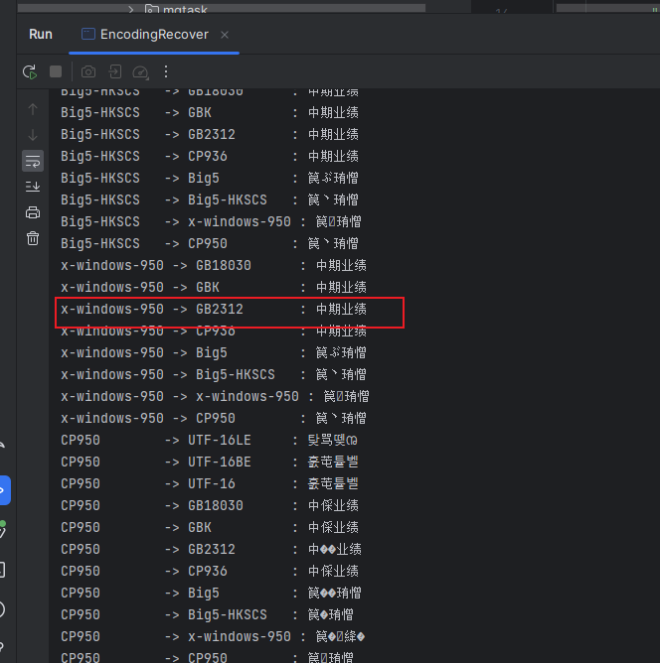
通过穷举之后,再结合实际,发现通过 x-windows-950 转到 GB3212 完全没问题,所有的数据都能正常转换了。问题解决。
From:一号门
Previous:用AI生成的一段穷举编码转换的java代码
COMMENTS